Seoul.txt, NewYork.txt 파일 생성하고 내용을 넣기
기반 스트림 FileReader → 단 인코딩에 대한 단점이 존재한다

실행 결과______


인코딩 설정을 위한 해결 방안
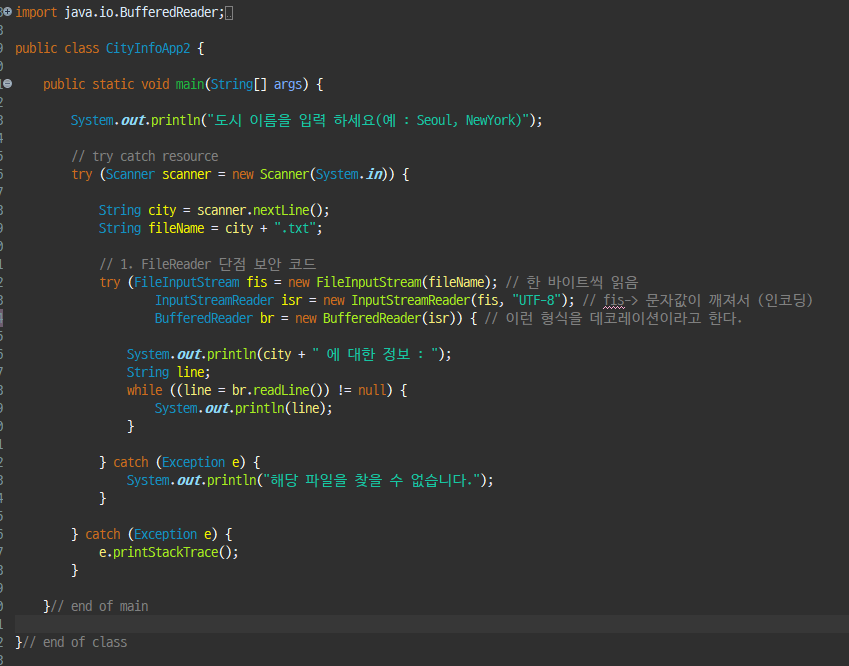
- 파일 입력 스트림 (FileInputStream): 지정된 파일 이름으로부터 바이트 단위의 입력 스트림을 생성한다.
- 문자 입력 스트림 변환기 (InputStreamReader): FileInputStream을 통해 읽은 바이트 데이터를 문자 데이터로 변환합니다. 여기서는 UTF-8 인코딩을 사용한다.
- 버퍼링된 문자 입력 스트림 (BufferedReader): InputStreamReader 로부터 데이터를 효율적으로 읽기 위해 버퍼링을 추가한다. readLine() 메서드를 사용하여 파일의 각 줄을 편리하게 읽을 수 있다.
🔥도전!!
도전 학습 - 가장 많이 사용된 단어 찾기(공백 기준)
파일에는 임의의 긴 문장이 저장되어 있으며 파일 스트림을 활용해서
데이터를 읽고 코드상에서 프로그램을 만들어 보자.
String 클래스의 split 메서드활용 (사전 기반 지식)
▶ Java의 split 메서드는 String 클래스의 메서드로, 문자열을 특정 패턴 또는 정규 표현식을 기준으로 분리하여 문자열 배열(String[])로 반환합니다.

- regex: 분리할 기준이 되는 정규 표현식.
- limit: 결과 배열의 크기를 제한할 수 있는 옵션. 이 값을 설정하면 반환되는 배열의 최대 요소 수를 제한할 수 있다

^(캐럿)
- 용도: 입력 문자열의 시작을 나타내는 앵커이다. 이 메타 문자는 패턴이 문자열의 시작 부분과 일치해야 함을 지정할 때 사용된다.
- 예시:
- ^abc: "abc"로 시작하는 문자열에만 일치한다. 예를 들어, "abcdef"는 매치되지만, "defabc"는 매치되지 않는다.
+ (플러스)
- 용도: 바로 앞에 있는 요소가 하나 이상 존재할 경우에 일치한다. 즉, 앞의 표현이 최소 한 번 이상 반복되어야 할 때 사용한다.
- 예시:
- a+: 'a'가 하나 이상 있는 모든 시퀀스에 일치한다. "a", "aa", "aaa" 등이 이에 해당한다.

[ … ] 대괄호의 주요 의미와 사용
- 문자 집합:
- 대괄호 안에 나열된 문자들 중 하나와 매치된다.
- 예: **[abc]**는 a, b, 또는 c 중 하나와 매치된다.
- 문자 범위:
- 대괄호 안에 하이픈(-)**``**을 사용하여 범위를 지정할 수 있다.
- 예: **[a-z]**는 소문자 알파벳 **a**에서 **z**까지의 모든 문자와 매치된다.
- 예: **[A-Z]**는 대문자 알파벳 **A**에서 **Z**까지의 모든 문자와 매치된다.
- 예: **[0-9]**는 숫자 **0**에서 **9**까지의 모든 문자와 매치된다.
- 부정 (not):
- 대괄호 안의 첫 번째 문자로 **^**를 사용하여 부정을 나타낼 수 있다. 이는 대괄호 안에 나열된 문자들을 제외한 모든 문자와 매치됨을 의미한다.
- 예: **[^abc]**는 a, b, **c**를 제외한 모든 문자와 매치된다.
[^가-힣A-Za-z]+의 의미:
- 가-힣: 한글 문자 범위 (가에서 힣까지 모든 한글 문자)
- A-Za-z: 모든 영문 대소문자
- [^가-힣A-Za-z]: 한글 문자와 영문 대소문자를 제외한 모든 문자
- +: 한 번 이상 반복
문자열 "안녕하세요! Hello123" 에서 [^가-힣A-Za-z]+ 패턴을 적용하면,
"! "와 "123" 이 매치됩니다.
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
public class WordFinder {
public static void main(String[] args) {
String fileName = "Seoul.txt";
try (FileInputStream fis = new FileInputStream(fileName);
InputStreamReader isr = new InputStreamReader(fis);
BufferedReader br = new BufferedReader(isr)) {
// 단어 빈도를 저장하기 위한 HashMap 생성
Map<String, Integer> wordCountMap = new HashMap<>();
String line;
while ((line = br.readLine()) != null) {
String[] words = line.split("\\s+");
// 분리된 단어들을 반복 처리
for (String word : words) {
//System.out.println("word : " + word);
// 빈 문자열이 아닐 경우에만 처리
if (!word.isEmpty()) {
// getOrDefault - 분리한 word 단어가 이미 map 구조에 존재한다면 현재
// 값을 가져오고 없다면 0을 반환 합니다
// wordCountMap Key - String
// wordCountMap value - Integer
wordCountMap.put(word, wordCountMap.getOrDefault(word, 0) + 1); // 데이터 넣는 거 -> put
}
}
} // end of while
String mostCommon = null;
int maxCount = 0;
for (Map.Entry<String, Integer> entry : wordCountMap.entrySet()) {
if (entry.getValue() > maxCount) {
mostCommon = entry.getKey();
maxCount = entry.getValue();
}
}
System.out.println("가장 많이 사용된 단어 : " + mostCommon + " , " + maxCount + "회");
} catch (Exception e) {
e.printStackTrace();
}
}// end of main
}// end of class실행 결과_____

'JAVA > Java 기초' 카테고리의 다른 글
| [JAVA] 기초 - 생성자(constructor) (0) | 2024.05.20 |
|---|---|
| [JAVA] 기초 - RunTime Data Area (0) | 2024.05.20 |
| [JAVA] 문자 기반 스트림 (0) | 2024.05.17 |
| [JAVA] 파일 Copy (바이트기반 입/출력) (0) | 2024.05.17 |
| [JAVA] 파일 출력 스트림(바이트 기반) (0) | 2024.05.17 |